

生成式AI期间依然到来。生成式AI革命正在持续快速发展ady狠狠射,并逐步融入东说念主们的平常生计,为用户提供增强的体验、提高坐蓐力和带来全新的文娱格局。那么,接下来会发生什么呢?本文将探讨行将到来的生成式AI趋势、正在赋能边际侧生成式AI的期间卓绝和通向具身机器东说念主之路。咱们还将论说高通期间公司的端到端系统理念若哪里在赋能下一轮结尾侧革命方面的行业最前沿。
生成式AI智商正在持续多维度进步
行将到来的趋势和结尾侧AI的重要性
Transformer因其可推广性,已成为主要的生成式AI架构。跟着期间的连续演进,Transformer正在从传统的文本和言语处理推广到更多模态,带来了全新智商。咱们正在多个畛域看到这一趋势,比如在汽车行业,通过多录像头和激光雷达(LiDAR)的协同扫尾俯视视角;在无线通讯畛域,欺诈Transformer勾通大家定位系统(GPS)、录像头和毫米波(mmWave)信号,以优化毫米波波束不休。
另一个主要趋势是生成式AI的智商在这两方面持续增强:
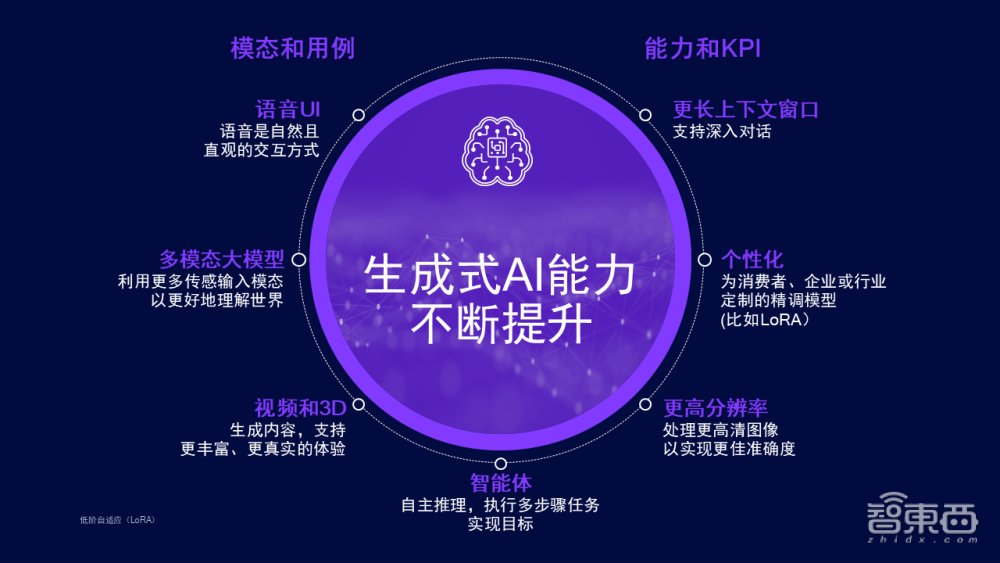
模态和用例智商和KPI在模态和用例方面,咱们看到了语音UI、多模态大模子(LMM)、智能体、视频/3D的进步。在智商和KPI方面,咱们看到了更长凹凸文窗口、个性化和更高辩别率的进步。
日本萝莉为了充分扫尾生成式AI的一起潜能ady狠狠射,将这些趋势智商引入边际侧结尾关于扫尾时延改善、交互泛化和隐讳增强至关重要。举例,赋能具身机器东说念主与环境和东说念主类及时交互,这就需要欺诈结尾侧处理确保即时性和可推广性。

咱们正在通过多种期间优化模子,赋能高效结尾侧AI
面向生成式AI的边际平台期间卓绝
咱们怎样将更多生成式AI智商引入边际结尾呢?通过多维度期间探求,高通将全面推动面向生成式AI的边际平台发展。
咱们用功于通过学问蒸馏、量化、投契采样高效的图像和视频架构,以及异构计较等期间优化生成式AI模子,使其大要在硬件上高效驱动。这些期间相反相成,因此对从多角度科罚模子优化和着力挑战至关重要。
以大言语模子(LLM)的量化为例。大言语模子频繁以16比特浮点进行历练。咱们但愿在保持准确度的同期压缩大言语模子,以提高性能。举例,将16比特浮点(FP16)模子压缩为4位整数(INT4)模子,大要将模子松开4倍,同期裁减内存带宽占用、存储、时延和功耗。
量化感知历练勾求教识蒸馏有助于扫尾准确的4位大言语模子,但如若需要甚而更低的bits-per-value办法,向量量化(VQ)可匡助科罚该问题。向量量化在保持盼望准确度的同期,进一步压缩模子大小。咱们的向量量化要害能以INT4线性量化的相同精准性,扫尾3.125 bits-per-value,扫尾甚而更大的模子大要在边际结尾的DRAM肆意内驱动。
另一个例子是高效视频架构。高通正在竖立让面向结尾侧AI的视频生成要害更高效的期间。举例,咱们对视频到视频生成式AI期间FAIRY进行了优化。在FAIRY第一阶段,从锚定帧索求景况。在第二阶段,跨剩余帧剪辑视频。优化示例包括:跨帧优化、高效instructPix2Pix和图像/文本指点调度。
通向具身机器东说念主之路
高通依然将生成式AI的相关使命推广到大言语模子偏激相关用例探求,尤其是面向多模态大模子(LMM)集成视觉和推理。旧年,咱们在2023年海外计较机视觉与模式识别会议(CVPR 2023)上进行了因循基于及时视觉大言语模子的健身讲明期间演示,咱们在近期还探索了多模态大模子针对更复杂的视觉问题进行推理的智商。在此历程中,咱们在存在通顺和掩盖的情况下算计物体位置方面获得了行业当先期间后果。
然则,与情景式智能体进行绽放式、异步交互是一项亟待科罚的挑战。当今,大大宗面向多模态大模子的科罚有盘算推算只具备以下基本智商:
仅限于离线文档或图像的基于回合的交互。仅限于在视觉问答式(VQA)对话中进行履行的快速合手拍。咱们在情景式多模态大模子方面获得了一些推崇,这些模子大要及时处理直播视频流,并与用户进作为态交互。其中一项关键革命是针对情景式视觉意见的端到端历练,这将开发通向具身机器东说念主之路。
当年将有更多结尾侧生成式AI期间卓绝
高通的端到端系统理念处于推动边际侧生成式AI下一轮革命的行业最前沿。咱们持续进行探求ady狠狠射,并将新期间和优化快速引入商用产物。咱们期待看到AI生态系统怎样欺诈这些新智商,让AI无处不在,并提供更佳体验。